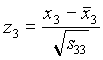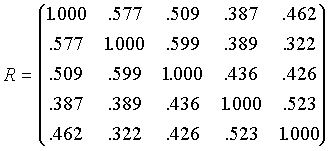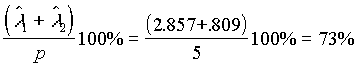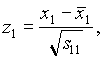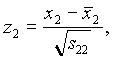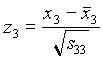| Tema X. La estadística y la Bolsa (I) |
LA ESTADÍSTICA Y LA BOLSA |
Análisis de las Componentes Principales:
una aplicación a la Bolsa
Vicente Quesada
Catedrático de Estadística e I.O.
Facultad de Matemáticas
Benjamín Hernández
Director de la Escuela Universitaria de Estadística
Universidad Complutense de Madrid
Supongamos un gestor que tiene en su cartera de inversión un gran número de acciones de diferentes empresas. Día a día recoge los precios de cierre de estos valores en el mercado bursátil para conocer el valor de mercado de sus activos. La variación de este valor global le indica si su inversión está siendo acertada o no.Introducción
Indice General

Indice Sectorial
 Indice
Particular
Indice
Particular
Gestión Activo a Activo Gestión siguiendo Indices
A la hora de la toma de decisiones, al gestor le gustaría poder tener alguna herramienta que le indicase cuál es el comportamiento general de su cartera sin tener que ir valorándola título a título. Le gustaría poder fijarse en unos índices genéricos (Indice General de la Bolsa, Indices Sectoriales, etc.) además de en algún índice específico de un activo determinado cuando éste tenga un comportamiento más particular. Esto le permitiría conocer cuáles son las causas de las pérdidas o ganancias que está experimentando en su cartera y si el valor de su cartera depende de las condiciones generales del mercado, de las condiciones específicas de un sector determinado, o bien de un determinado activo que está teniendo un comportamiento especial.
Imaginemos, que nuestro gestor invierte en valores perteneciente al IBEX 35. En este caso, el indice que estara buscando sera, grossomodo, el indice IBEX 35, publicado por Bolsa de Madrid diariamente. Pero, qué puede hacer el gestor cuando invierte en empresas de las que no existe ningún indice publicado, por ejemplo si invierte en difentes valores de empresas europeas. La solucion la encontrara en el Análisis de Componentes Principales.
Para poder obtener los valores de los Indices que le van a permitir nuestro gestor ha decidido utilizar el Análisis de Componentes Principales (PCA). El PCA es una sencilla y potente herramienta estadística utilizada ampliamente en el Análisis Financiero. Para poder calcular estas componentes principales el gestor necesita tener una serie histórica de precios que le permita conocer cuál ha sido el comportamiento histórico de sus títulos, de manera individual y comparándolos con el comportamiento del mercado, durante los últimos meses. Una vez calculados estos Indices, o componentes principales, podrá utilizarlos junto a sus herramientas habituales para la toma de decisiones de inversión.
Como primera indicación, podríamos decir que el PCA es una herramienta adecuada cuando se quiere conseguir una comprensión del funcionamiento de un determinado mercado bursátil reduciendo la complejidad de su estudio.
El PCA consiste en una técnica estadística de reducción de la información disponible sobre un conjunto de datos. Lo que se hace es condensar la matriz de correlaciones entre las variables (cómo están relacionados los precios de los diferentes valores) en unas "componentes principales" que nos darán casi la misma información. Dicho de otra forma, el PCA es una técnica estadística que permite transformar un conjunto de variables intercorrelacionadas en otro conjunto de variables no correlacionadas, denominadas factores. Los factores son combinación lineal de las variables originales.
El PCA trata principalmente de explicar la estructura de varianza-covarianza a través de unas pocas combinaciones lineales de las variables originales. Podríamos resumir sus objetivos principales en:
Objetivos del PCA
Reducción de los datos
Interpretación de los datos
Podemos resumir esta técnica como un método de transformar las variables originales en unas nuevas variables independientes. Cada componente principal es una combinación lineal de las variables originales.
Si tenemos un mercado cuyo funcionamiento depende de p variables, normalmente necesitaremos esas p variables para poder reproducir su variabilidad total (su comportamiento), sin embargo a menudo gran parte de esta variabilidad viene provocada por un pequeño número k de Componentes Principales. Cuando esto es así, hay casi la misma información en las k componentes que en el sistema original de p variables. Es decir nuestro gestor debe seguir todas las acciones (p variables) para conocer el comportamiento total su cartera, pero puede optar por seguir la evolución de unos pocos índices (k componentes principales) que pueden explicarle la casi totalidad del comportamiento de su cartera original. Es importante destacar que el gestor debe ser consciente que hay una parte de su cartera que no le van a explicar los índices.
Tema X. La estadística y la Bolsa (I)
El Análisis de las Componentes Principales
Para facilitar la explicación vamos a poner un ejemplo práctico de mercado. Nuestro inversor, D. José Bolsas, tiene en su cartera tres acciones de tres empresas distintas. D. José ha recogido durante la últimas 10 semanas la evolución del valor de sus acciones:
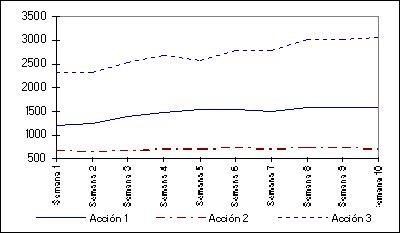
Acción 1 |
Acción 2 |
Acción 3 |
|
Semana 1 |
1200,00 |
678,00 |
2323,00 |
Semana 2 |
1232,43 |
647,59 |
2315,96 |
Semana 3 |
1383,78 |
686,94 |
2520,10 |
Semana 4 |
1462,70 |
707,52 |
2688,47 |
Semana 5 |
1555,83 |
704,83 |
2581,50 |
Semana 6 |
1561,31 |
740,61 |
2795,43 |
Semana 7 |
1490,09 |
716,17 |
2802,57 |
Semana 8 |
1577,74 |
746,04 |
3030,77 |
Semana 9 |
1577,74 |
731,56 |
3037,90 |
Semana 10 |
1588,70 |
712,54 |
3059,29 |
Don José se plantea si sería posible conocer el rendimiento de su cartera conociendo un Indice General a todas sus acciones. Si pudiera hacerlo, podría incluso prever cual será el valor de su cartera en función de la evolución prevista del Indice General. D. José encarga a un analista que estudie cómo se mueve su cartera.
¿Es posible un Índice que siga el movimiento de mi cartera de acciones?
![]()
¿Cómo estará relacionado el rendimiento del índice con el de cada una de mis acciones?
El analista le presenta su informe indicándole que el 73% del comportamiento de su cartera viene dado por un Indice que es la combinación lineal de los rendimientos de todas las acciones que él posee. Este índice podría interpretarlo como un indicador general del mercado. Esto quiere decir que las casi tres cuartas partes del rendimiento de sus acciones tienen un origen común que es el comportamiento general del mercado.
El analista le comunica además que para la primera semana de su estudio, este índice le supuso un rendimiento a cada uno de los activos de 0,025. Es decir si éste índice fuera el único causante de las ganancias de su cartera, D. José habría ganado un 2,5% en cada una de sus acciones. En otras palabras, si en un futuro no hubiese cambios fundamentales en el mercado (normalmente expectativas económicas), si este índice subiese un 5% sus acciones subirían un 5%.
Técnicamente podemos afirmar que el analista ha utilizado un análisis de Componentes Principales.
En su enfoque más general, el PCA trata de identificar las componentes que mejor describen nuestro mercado y proporciona una estimación de la probable precisión que vamos a obtener con cada uno de los modelos posibles. Esta descomposición proporciona un conocimiento muy útil del comportamiento y complejidad del mercado.
Tema X. La estadística y la Bolsa (I)
Herramienta estadística necesaria para el PCA
Para poder realizar el PCA necesitamos un algoritmo que analice nuestro histórico de precios y nos devuelva las componentes y sus factores de escala. Además es necesario conocer con qué valores debemos ponderar cada una de las componentes para poder describir el movimiento diario de un día cualquiera.
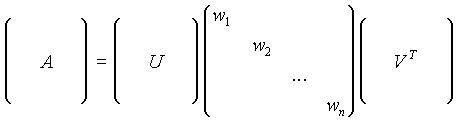
Existe un método conocido como "Singular Value Decomposition" (SVD) que hace justamente lo que estamos buscando. El algoritmo SVD divide una matriz A con el histórico de las variaciones de los precios en un producto de tres matrices U·w·V donde las columnas de V son las Componentes Principales. Los elementos de la diagonal de w (que es una matriz diagonal) son factores de escala para cada una de las componentes, y la matriz U expresa los cambios de cada día como la suma ponderada de estas nuevas componentes.
Propiedades que deberían cumplir las Componentes Principales
1. Nuestro algoritmo generador de Componentes Principales debería proporcionarnos, además de las Componentes Principales, una matriz con las cantidades de cada componente que se han observado cada uno de los días. Con estas dos matrices debería ser posible reconstruir la matriz original de los cambios diarios de los precios. Una medida de la cantidad de información proporcionada por cada componente principal es su varianza. Por esta razón las componentes principales se ordenan en orden de varianza decreciente. Por lo tanto la primera componente principal será aquella que nos proporcione la mayor cantidad de información, mientras que la última será la que menos información nos proporcione (una componente principal con varianza nula no hace ninguna distinción entre los elementos de la serie).
2. Si dos componentes son iguales, intuitivamente deberíamos poder reducirlas a una sola, y sumar las cantidades observadas de cada una. No debería existir ninguna ventaja adicional por tener dos copias de una componente, pero ¿qué pasa si dos componentes son similares?: en ese caso deberíamos poder reducirlas a una, o bien al menos poder juntar las parte en la que se parecen. Esto nos lleva a imponer como condición que las componentes principales sean completamente diferentes, matemáticamente hablando, deberían ser independientes, de forma que ninguna componente tenga una parte de alguna de las otras componentes.
3. Consideremos la matriz de las cantidades observadas de cada componente en los diferentes días. Si hubiese dos componentes que siempre estuvieran presentes en la misma cantidad, estas componentes podrían reducirse a una única. Si dos componentes estuvieran siempre en cantidades similares, entonces las partes cuya presencia está correlacionada podría juntarse. Debemos asimismo imponer una condición de ortogonalidad, esta vez entre los vectores de las cantidades de cada componente de las cuales se componen cada uno de los cambios diarios.
Con las condiciones anteriormente descritas, seguimos teniendo un grado de libertad. Para eliminar esta ambigüedad, debemos forzar a que cada una de las componentes sea de longitud unidad, tal y como ocurre con los vectores de las "cantidades", y separar cada uno de los "pesos" de cada componente en un vector adicional llamado w.
Las condiciones anteriores son suficientes para enunciar las ecuaciones necesarias.
En estas ecuaciones A representa la matriz original de los cambios diarios, U es la matriz que determina cuanto de cada uno de los diferentes componentes aparece cada uno de los días, V es una matriz cuadrada cuyas columnas son las Componentes Principales, y las w´s son los pesos.
Para reconstruir la matriz original, necesitamos:
Las Componentes Principales son ortogonales y de longitud unidad:
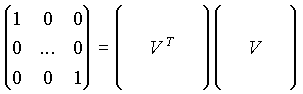
Las cantidades de cada componente presentes en cada una de las muestras son ortogonales:
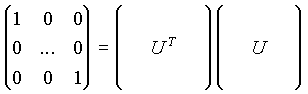
Independientemente de la interpretación que les demos a las Componentes Principales, les obligamos a que cumplan estas tres ecuaciones. Estas tres ecuaciones bastan (son suficientes), y tienen una única solución.
Para facilitar el seguimiento matemático proponemos un ejemplo con únicamente dos variables (en realidad no tendría mucho sentido pues no podemos reducir en gran medida el número de variables a analizar). Supongamos ahora que tenemos los rendimientos semanales de dos compañías durante ocho semanas.
Semana |
Compañía 1 |
Compañía 2 |
1 |
-0,044068 |
0,020704 |
2 |
0,039007 |
0,038540 |
3 |
-0,394570 |
-0,029297 |
4 |
0,039568 |
0,024145 |
5 |
-0,031142 |
-0,007941 |
6 |
0,000000 |
-0,020080 |
7 |
0,021429 |
0,049180 |
8 |
0,045454 |
0,046375 |
Para facilitar la interpretación de los resultados vamos a restar la media de la muestra a cada una de las observaciones,
![]()
![]()
siendo
y
nos queda,
Semana |
Compañía 1 |
Compañía 2 |
1 |
-0,003528 |
0,005501 |
2 |
0,079547 |
0,023337 |
3 |
-0,354030 |
-0,044500 |
4 |
0,080108 |
0,008942 |
5 |
0,009398 |
-0,023144 |
6 |
0,040540 |
-0,035283 |
7 |
0,061969 |
0,033977 |
8 |
0,085994 |
0,031172 |
Nótese que este cambio de origen hace que las medias de m1 y m2 sean iguales a cero, pero no altera las varianzas de las muestras S12 y S22 o la correlación entre ambas r.
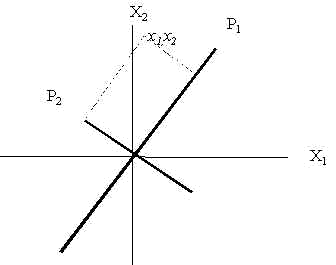
La idea básica es crear dos nuevas variables P1 y P2, llamadas componentes principales, que serán funciones lineales de m1 y m2, y que podemos por tanto expresar como:
![]()
![]()
Destaquemos que para cualquier conjunto de valores de los coeficientes a11, a12, a21, a22, podemos introducir las ocho observaciones de m1 y m2 y obtener ocho valores de P1 y P2.
Las medias y las varianza de los ocho valores de P1 y P2 son
![]()
donde S12 y S22 son las varianzas muestrales y r la correlación de las muestras.
Los coeficientes se eligen de forma que satisfagan los siguientes tres requisitos que hemos señalado anteriormente:
1. La varianza de P1 es lo mayor posible.
2. Los ocho valores de P1 y P2 no están correlacionados.
3. Las cantidades de cada componente presentes en cada una de las muestras son ortonormales ()
Gráficamente viene representado de la siguiente forma
La solución matemática al problema de las componentes principales la halló Hotelling en 1933. El análisis de las componentes principales no es sino un giro de los ejes originales m1 y m2 a unos nuevos ejes P1 y P2. El ángulo de rotación lo determinan las tres condiciones que acabamos de imponer. Para cualquier punto dado x1, x2 los valores de P1 y P2 se encuentran dibujando líneas perpendiculares a los nuevos ejes P1 y P2. Los ocho valores de P1 así obtenidos tendrán la máxima varianza, mientras que los distintos ocho valores P1 y P2 tendrán correlación nula.
Aplicando el algoritmo SVD a los valores de nuestro ejemplo obtenemos los siguientes valores de w, U y V.
Componentes Principales |
|||
Primera |
Segunda |
||
w's |
0,39265 |
0,05854 |
|
V |
Compañía 1 |
0,98961 |
0,14375 |
Compañía 2 |
0,14375 |
-0,98961 |
|
Sem. 1 |
-0,00688 |
-0,10166 |
|
Sem. 2 |
0,20903 |
-0,19918 |
|
Sem. 3 |
-0,90856 |
-0,11711 |
|
U |
Sem. 4 |
0,20517 |
0,04556 |
Sem. 5 |
0,01521 |
0,41436 |
|
Sem. 6 |
0,08926 |
0,69606 |
|
Sem. 7 |
0,16862 |
-0,42223 |
|
Sem. 8 |
0,22815 |
-0,31581 |
Veamos ahora qué significan estos números.
La Compañía 1 tiene una primera componente principal de 0,98961 y una segunda componente principal de 0,14375. Estas componentes vienen ajustadas por unos pesos de 0,39265 para la primera y 0,05854 para la segunda.
La octava semana la primera componente principal se encontraba presente en 0,22815, mientras que la segunda se encontraba presente en -0,31581.
Es decir para poder reproducir la variación que experimentó la rentabilidad de la Compañía 1 debemos realizar la siguiente operación:
Estas componentes no nos serían muy útiles tal cual pues las unidades no son las adecuadas. Aunque las columnas de V son las verdaderas componentes, a menudo es útil cambiar la escala para darles sus proporciones naturales, en vez de dejar que todas sigan teniendo longitud unitaria. Como acabamos de ver, los cambios semanales vienen dados por las componentes principales multiplicadas por unos pesos y por elemento de U. Conocemos los pesos w’s. Sabemos además que las columnas de U tienen longitud la unidad (Puede comprobarse que la raíz cuadrada de la suma de los cuadrados de los elementos de cualquiera de las dos columnas de U es uno). Por tanto el elemento medio de U tendrá un valor ± 1/Ö 8.
Tema X. La estadística y la Bolsa (I)
Número de Componentes que vamos a conservar
Como hemos comentado anteriormente, uno de los objetivos principales del PCA es la reducción de la dimensionalidad del problema. Como los componentes principales se ordenan en orden decreciente de varianza, podemos seleccionar las primeras componentes como representativas de todo el conjunto de variables originales. El número de componentes seleccionado puede determinarse examinando la proporción de varianza total que explica cada componente. La proporción acumulada de varianza total nos indica cuanta información hemos retenido al seleccionar un número dado de componentes principales.
Podemos calcular la proporción del total de varianza que explica la k-ésima componente principal como
.
Sin querer entrar en este documento en el desarrollo matemático completo de las Componentes Principales, diremos simplemente que siendo R la matriz de covarianza de las muestras mi, l i los autovalores de dicha matriz y ê i los autovectores asociados, la proporción total de varianza explicada por las k primeras componentes principales vendría dada por:
, siendo los autovectores las Componentes Principales de las muestras mi.
Cuándo es apropiado utilizar el análisis PCA
A la hora de estudiar una serie mediante un análisis de componentes principales, debemos preguntarnos primero si nuestros datos son adecuados para un estudio de este tipo. Afortunadamente, son los datos mismos los que nos van a proporcionar la respuesta a esta pregunta.
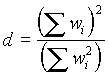
Podemos ver d como la dimensionalidad del mercado.
¿Cómo puede esto ayudarnos a juzgar si tiene sentido hacer un análisis PCA?. Las componentes principales se pueden ver como una herramienta para reducir la dimensionalidad de los problemas. Empezando con N series cambios en precios, PCA es capaz de expresar estas N series en función de A componentes, (ignorando ese pequeño término basura que contribuyen en una fracción de dimensión). El PCA es más estable, y por tanto d es de mayor utilidad, cuando la dimensionalidad de los datos es baja (i.e. d<<<n). Si partimos de 12 series de datos y d nos sugiere que la dimensión de los datos es 9, el PCA no puede reducir la dimensión de los datos de manera significativa y por tanto el PCA no es, probablemente, la mejor herramienta con la que analizar estos datos.
Tema X. La estadística y la Bolsa (I)
Identificación de los componentes "basura"
No existen ningunas reglas rápidas y de fácil aplicación que nos permitan determinar qué componentes son las que debemos guardar (i.e. debemos cubrir) y cuales debemos ignorar. Sin embargo se pueden dar dos recomendaciones de gran utilidad:
- Las componentes con w’s bajas, no tienen por lo general gran importancia. Desafortunadamente no existe ninguna regla que nos diga cómo de pequeñas han de ser estas w´s para que las componentes asociadas puedan ser ignoradas. La forma más fácil de ver ésto es aplicar un factor de escala a los vectores normalizados (como hemos descrito anteriormente) y mostrarlos gráficamente. No existe ninguna forma de evitar la subjetividad en esta fase del estudio: aquí siempre será importante la experiencia del mercado real que tengamos.
- Si dos componentes tienen las mismas w’s entonces la elección de las contiene un arbitrariedad. Las componentes calculadas podrían ser sustituidas por otro par de componentes situadas sobre el mismo plano (i.e. por una combinación ortonormal de las componentes con idénticas w´s. En la práctica, utilizando datos reales, nunca se encuentran componentes con los mismos w´s. Sin embargo, si dos w´s son muy parecidas, en la práctica esas dos componentes podrían haber interferido. La consecuencia práctica es que si existe un bloque de componentes con valores w´s similares, entonces se debería pensar que o bien todos esos componentes son basura, o bien uno debería cubrir la exposición que se tenga a todos ellos. No tendríamos ninguna ventaja si solo nos cubriéramos frente a uno de ellos y no frente a los demás Normalmente los grupos de componentes con w´s similares tienes w´s relativamente bajos y pueden ser ignorados.
También hay que destacar que el signo de una componente no tiene ningún significado - los componentes sólo están definidos dentro de un factor de -1 +1. Los programas de software devolverán componentes con signos asignados de manera arbitraria, aunque consistentes con el signo de los elementos de la columna correspondiente de U. De otra forma, si un mercado tiene una primera componente que es un movimiento paralelo hacia arriba, y otro tiene una primera componente que es un movimiento paralelo hacia abajo, el valor de estas componentes no será necesariamente diferente.
Consideraciones a la hora de seleccionar y tratar los datos
Como ya hemos comentado, el PCA se utiliza principalmente como una técnica exploratoria, con poco uso de los tests estadísticos o de los intervalos de confianza. Por esta razón, no son necesarias hipótesis formales sobre la distribución que sigue la serie. No obstante, la información proporcionada por este análisis será bastante más sencilla de interpretar si se cumplen ciertas condiciones.
- Como con todos los estudios estadísticos, la interpretación de los datos de una muestra aleatoria de una población bien definida es más sencilla que la interpretación de una muestra que ha sido tomada de manera poco ordenada.
- Si las observaciones provienen de una distribución simétrica, o se utiliza una para su transformación, los resultados serán más fáciles de comprender que si se analizan series asimétricas. Obviamente siempre deberíamos buscar y eliminar los "outliers" - en nuestro caso podrían ser precios de las acciones el día que pagan dividendos- de nuestras series.
Si se va a utilizar el PCA para buscar la existencia de redundacias en los datos, entonces es importante que las observaciones sean medidas con gran precisión. De otra forma será bastante difícil detectar las interrelaciones entre las diferentes variables.
Si queremos construir una serie de las cotizaciones de un determinado activo, deberemos tomar las muestras siempre a la misma hora del día y deberemos tener cuidado y ajustar nuestros precios en función del pago de dividendos y de los posibles splits (divisiones de una acción en varias de menor valor nominal) y ajustes de nominal que se hagan.
Ejemplo
(Este ejemplo utiliza datos reales de empresas que cotizan en Wall Street).
Supongamos que D. Mariano Wall Street posee acciones de cinco compañías diferentes. Estas cinco compañías se dividen en dos sectores: tres químicas y dos petroleras:
Cartera de D. Mariano Wall Street
Química 1
Química 2
Química 3
Petrolera 1
Petrolera 2
D. Mariano posee datos semanales de los rendimientos semanales (definidos como Precio de cierre del Viernes menos precio de cierre del Viernes anterior dividido, todo ello, por el precio de cierre del Viernes anterior) en un total de 100 observaciones. Tras analizar las series de las observaciones en las 100 sucesivas semanas comprueba que los datos están independientemente distribuidos, pero las rentabilidades de las diferentes acciones están correladas (como podía suponer pues los precios se mueven en respuesta a las condiciones económicas generales).
Mariano realiza un Análisis de Componente Principales para ver qué conclusiones obtiene. Para ello utiliza uno de los paquetes de software estadístico del mercado.
Sean x1, x2, …, x5 las observaciones semanales de la rentabilidad de las respectivas acciones. Se como medias:
Como matriz de covarianzas de las observaciones estandarizadas (donde s indefifica a la varianza de la serie)
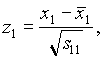
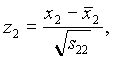
obtiene:
Los autovalores y autovectores normalizados de la matriz R resultan:
,
,
,
,
,
Utilizando las variables estandarizadas, obtenemos las dos primeras componentes principales
Estas dos componentes explican el
de la variación total (estandarizada) de la cartera de acciones. La primera componente representa un índice bursátil de las acciones. Se la llamaría la componente del mercado.
La segunda componente representa un contraste entre las acciones químicas y las petroleras. Es la componente sectorial. De esta forma la mayor parte de la variación de las rentabilidades semanales es debida a la actividad del mercado y en bastante menor medida del sector industrial.
El resto de componentes no tienen fácil interpretación y, colectivamente, representan la variación debida a la acción específica que consideremos. De cualquier manera, no representan una importante variación del total.
Tema X. La estadística y la Bolsa (I)
Software estadístico que contiene Análisis de Componentes Principales:
- Statgraphics
- SPLUS
- SPSS
Caso a Resolver por el alumno
D. José Bolsas es un inversor que posee una cartera de acciones de seis compañías diferentes.
Cartera de D. José Bolsas
Argentaria
Banco Santander
BBV
Unión Fenosa
Iberdrola
Endesa
D.José posee datos semanales de los rendimientos semanales (definidos como Precio de cierre del Viernes menos precio de cierre del Viernes anterior dividido, todo ello, por el precio de cierre del Viernes anterior) en un total de 100 observaciones. Tras analizar las series de las observaciones en las 100 sucesivas semanas comprueba que los datos están independientemente distribuidos, pero las rentabilidades de las diferentes acciones están correladas.
D. José, tras recomendación de su amigo D. Mariano Wall Street, realiza un Análisis de Componente Principales para ver qué conclusiones obtiene. Para ello utiliza uno de los paquetes de software estadístico del mercado.
Sean x1, x2, …, x6 las observaciones semanales de la rentabilidad de las respectivas acciones. Se tiene que tiene unas medias de:
Como matriz de covarianzas de las observaciones estandarizadas
obtiene:
Los autovalores y autovectores normalizados de la matriz R resultan:
,
,
,
,
,
,